
問題:AI 看不到網頁內容、無法爬蟲、分析資料?
你有沒有遇過這種情況?
你:「幫我看看這篇文章在講什麼」(貼了一個網址)
AI:「抱歉,我無法直接存取網頁內容...」這是因為 AI 助理本身看不到網頁,如果他手上沒工具。
解法:給 AI 一組工具,讓它可以「出門看網頁」。
目前主流有三種工具,各有擅長的場景。這篇會幫你搞懂:什麼時候用哪個、怎麼裝、怎麼設定。
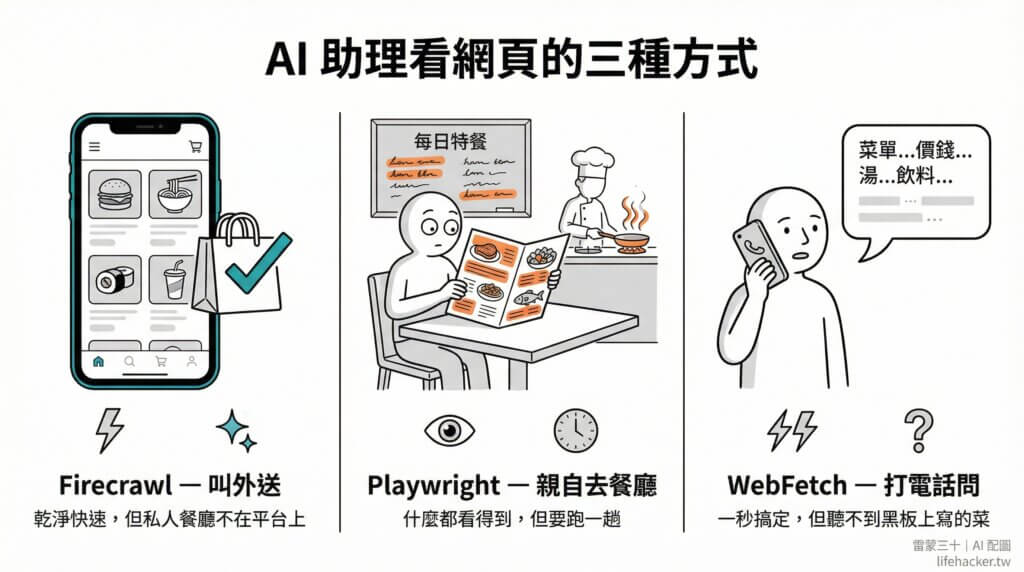
三個工具是什麼?用餐廳比喻

想像你想知道一家餐廳的菜單內容:
Firecrawl — 外送平台
你打開外送 App,搜尋餐廳名稱,App 直接把菜單整理好給你看:菜名、價格、照片,排版清清楚楚。
- 優點:最快、最乾淨、自動整理格式
- 缺點:如果餐廳沒有上架外送平台(像是私人社群),你就看不到
- 費用:免費額度每月 500 次,一般使用綽綽有餘
Playwright — 親自走一趟
你出門搭車到餐廳,坐下來翻菜單、跟店員對話、拍照記錄。什麼都看得到,因為你就在現場。
- 優點:什麼都能看到(包括需要登入的內容、社群貼文)
- 缺點:比較慢(要開瀏覽器、載入頁面)
- 費用:完全免費
WebFetch — 打電話問
你直接打電話給餐廳:「請問你們有什麼菜?」對方口頭念給你聽。
- 優點:最快、零成本
- 缺點:如果菜單是寫在黑板上的(動態網頁),電話裡聽不到
- 費用:完全免費
完整比較表
| Firecrawl | Playwright | WebFetch | |
| 一句話定位 | 雲端爬蟲,AI 優化輸出 | 真實瀏覽器自動化 | 簡易 HTTP 請求 |
| 輸出格式 | 乾淨的 Markdown | 網頁 DOM / 截圖 | HTML 轉 Markdown |
| 處理 JavaScript | ✅ 可以 | ✅ 可以 | ❌ 不行 |
| 社群媒體 | ❌ 會被擋 | ✅ 唯一選擇 | ❌ 拿到空殼 |
| 需要登入的網頁 | ❌ 不支援 | ✅ 可以模擬登入 | ❌ 不支援 |
| 速度 | ⚡ 快(2~5 秒) | 🐢 較慢(5~15 秒) | ⚡⚡ 最快(1~2 秒) |
| 費用 | 免費 500 次/月 | 完全免費 | 完全免費 |
| 安裝複雜度 | 需要 API Key | 需要安裝瀏覽器引擎 | 內建,不用裝 |
什麼時候用哪個?決策流程
收到一個網址,想讓 AI 看內容
│
├─ 是 Notion 頁面?
│ → 用 Notion API(永遠不用爬蟲工具)
│
├─ 是社群媒體?(FB / IG / Threads / X)
│ → 直接用 Playwright
│
├─ 是靜態網頁?(GitHub、API 文件、技術部落格)
│ → 先試 WebFetch(最快),失敗再換
│
└─ 一般網頁?(新聞、部落格、產品頁面)
→ 先用 Firecrawl(預設首選)
├─ 成功 → 完成
└─ 失敗 → 換 Playwright記住這個優先順序:
Firecrawl → Playwright → WebFetch
社群媒體例外,直接跳到 Playwright。
安裝與設定
前提
你已經安裝了 Claude Code(如果還沒,先看 Claude Code 完整入門教學)。
這三個工具都可以透過 MCP(Model Context Protocol)簡單連接的。
► 如果你不知道 MCP 是什麼,先看 MCP 設定入門(系列文章,敬請期待)。
Firecrawl — 雲端爬蟲
Step 1:取得 API Key
- 到 firecrawl.dev 註冊帳號
- 進入 Dashboard → API Keys
- 點「Create API Key」,複製 Key
Step 2:設定 MCP
在 Claude Code 的 MCP 設定檔加入:
{
"mcpServers": {
"firecrawl": {
"command": "npx",
"args": ["-y", "firecrawl-mcp"],
"env": {
"FIRECRAWL_API_KEY": "你的 API Key"
}
}
}
}Step 3:測試
跟 AI 說:「幫我用 Firecrawl 看一下這個網址的內容」,貼上任意網頁連結。
額度說明:
- Hobby Plan(免費):每月 500 credits
- 抓一個網頁 = 1 credit
- 遞迴爬整個網站 = 每個頁面 1 credit(小心使用)
- 以一般用量來說,一天抓 10~15 個網頁,免費額度用不完
Playwright — AI 用的瀏覽器
Step 1:安裝瀏覽器引擎
打開終端機,執行:
npx playwright install chromium這會下載一個 Chromium 瀏覽器(約 200MB),AI 會用它來「打開」網頁。
Step 2:設定 MCP
{
"mcpServers": {
"playwright": {
"command": "npx",
"args": ["@anthropic/mcp-playwright"]
}
}
}Step 3:測試
跟 AI 說:「幫我用 Playwright 打開這個 Threads 貼文,把內容抓下來」。
使用情境:
- 抓 Facebook / Instagram / Threads 的公開貼文
- 需要截圖的場景(AI 會幫你拍網頁畫面)
- 需要互動的網頁(點按鈕、填表單、滾動頁面)
WebFetch — 內建工具
不用安裝! 這是 Claude Code 內建的功能。
直接跟 AI 說:「幫我看一下這個 GitHub 頁面在講什麼」,它就會用 WebFetch 去抓。
適合場景:
- GitHub README、API 文件
- 技術部落格(通常是靜態網頁)
- 任何不需要 JavaScript 渲染的簡單頁面
不適合:
- 社群媒體(拿到空殼)
- 需要登入的網頁
- 重度使用 JavaScript 的 SPA 網站
常見場景對照
| 我想做的事 | 用哪個工具 | 原因 |
| 看一篇部落格文章 | Firecrawl | 輸出乾淨,格式好 |
| 抓一篇 Threads 貼文 | Playwright | 社群媒體只有它能抓 |
| 看 GitHub 上的 README | WebFetch | 靜態頁面,最快 |
| 抓 Facebook 粉專貼文 | Playwright | 社群媒體 |
| 查一個 npm 套件的文件 | WebFetch | 靜態頁面 |
| 把一整個網站的內容爬下來 | Firecrawl(crawl) | 支援遞迴爬取 |
| 需要網頁截圖 | Playwright | 唯一能截圖的 |
| 看一篇新聞報導 | Firecrawl | 新聞網站通常有複雜排版 |
三個教訓
在實際使用這些工具的過程中,我學到幾件事:
1. 社群媒體不要浪費時間試 Firecrawl
FB、IG、Threads 這些平台會封鎖雲端爬蟲的 IP。每次嘗試都要等它超時失敗才換下一個,白白浪費時間。看到社群媒體的網址,直接用 Playwright。
2. 不要小看 WebFetch
很多時候你只是想快速看一下某個頁面的內容,WebFetch 一秒就搞定。不是所有場景都需要出動 Firecrawl 或 Playwright。
3. 了解「Threads 官方 API」的限制
即使你裝了 Threads API,它也只能操作你自己帳號的貼文(發文、回覆、看數據)。想看別人的貼文?只能靠 Playwright 去「看」公開頁面。這不是工具的問題,而是平台的設計。
總結
一般網頁 → Firecrawl(乾淨快速)
社群媒體 → Playwright(唯一選擇)
靜態文件 → WebFetch(秒速完成)
Notion → Notion API(專用工具)三個工具互相補位,覆蓋了 95% 的網頁抓取場景。不用額外花錢買第三方服務,這個組合就是目前 AI Agent 生態圈最主流的配置。
相關閱讀:MCP 設定入門(系列文章,敬請期待)、Claude Code 完整入門教學




